fit_one_spline <- function(dat, k, scale, label) {
tryCatch({
fit <- flexsurvspline(Surv(time_months, status) ~ 1, data = dat, k = k, scale = scale)
fit_aic <- as.numeric(AIC(fit) %||% NA_real_)
fit_ll <- as.numeric(fit$loglik %||% NA_real_)
tibble(
dist_label = label,
fit = list(fit),
converged = TRUE,
error = NA_character_,
aic = fit_aic,
loglik = fit_ll,
n = nrow(dat),
events = sum(dat$status)
)
}, error = function(e) {
tibble(
dist_label = label,
fit = list(NULL),
converged = FALSE,
error = conditionMessage(e),
aic = NA_real_,
loglik = NA_real_,
n = nrow(dat),
events = sum(dat$status)
)
})
}
# Function to apply 5-to-7 year treatment effect waning on hazards
apply_efficacy_waning <- function(psm_df, start_week = 260, end_week = 364) {
# Separate arms
ctrl <- psm_df |> filter(arm == "Placebo + chemo") |> arrange(time_weeks)
act <- psm_df |> filter(arm == "Pembro + chemo") |> arrange(time_weeks)
n_weeks <- nrow(ctrl)
if (n_weeks == 0 || nrow(act) == 0) return(psm_df)
# Ensure survival values are non-increasing and positive
clean_surv <- function(x) {
pmax(pmin(cummin(x), 1), 1e-10)
}
ctrl$PFS <- clean_surv(ctrl$PFS)
ctrl$OS <- clean_surv(ctrl$OS)
act$PFS <- clean_surv(act$PFS)
act$OS <- clean_surv(act$OS)
# Extract vectors
S_c_pfs <- ctrl$PFS
S_c_os <- ctrl$OS
S_a_pfs <- act$PFS
S_a_os <- act$OS
# Compute weekly hazards (using S(0) = 1)
get_hazards <- function(S) {
haz <- numeric(length(S))
haz[1] <- -log(S[1])
for (t in 2:length(S)) {
haz[t] <- -log(S[t] / S[t-1])
}
pmax(haz, 0)
}
h_c_pfs <- get_hazards(S_c_pfs)
h_c_os <- get_hazards(S_c_os)
h_a_pfs <- get_hazards(S_a_pfs)
h_a_os <- get_hazards(S_a_os)
# Compute waning weights
w <- numeric(n_weeks)
for (t in 1:n_weeks) {
week_num <- ctrl$time_weeks[t]
if (week_num < start_week) {
w[t] <- 0
} else if (week_num > end_week) {
w[t] <- 1
} else {
w[t] <- (week_num - start_week) / (end_week - start_week)
}
}
# Compute waned hazards for active arm
h_a_pfs_waned <- (1 - w) * h_a_pfs + w * h_c_pfs
h_a_os_waned <- (1 - w) * h_a_os + w * h_c_os
# Reconstruct survival probabilities for active arm
S_a_pfs_waned <- numeric(n_weeks)
S_a_os_waned <- numeric(n_weeks)
S_a_pfs_waned[1] <- exp(-h_a_pfs_waned[1])
S_a_os_waned[1] <- exp(-h_a_os_waned[1])
for (t in 2:n_weeks) {
S_a_pfs_waned[t] <- S_a_pfs_waned[t-1] * exp(-h_a_pfs_waned[t])
S_a_os_waned[t] <- S_a_os_waned[t-1] * exp(-h_a_os_waned[t])
}
# Update active arm values
act$PFS <- S_a_pfs_waned
act$OS <- S_a_os_waned
# Bind arms back together
res <- bind_rows(ctrl, act) |>
mutate(
PFS = pmin(PFS, OS), # Apply logic cap after waning
PF = PFS,
PD = pmax(OS - PFS, 0),
Dead = pmax(1 - OS, 0)
)
return(res)
}
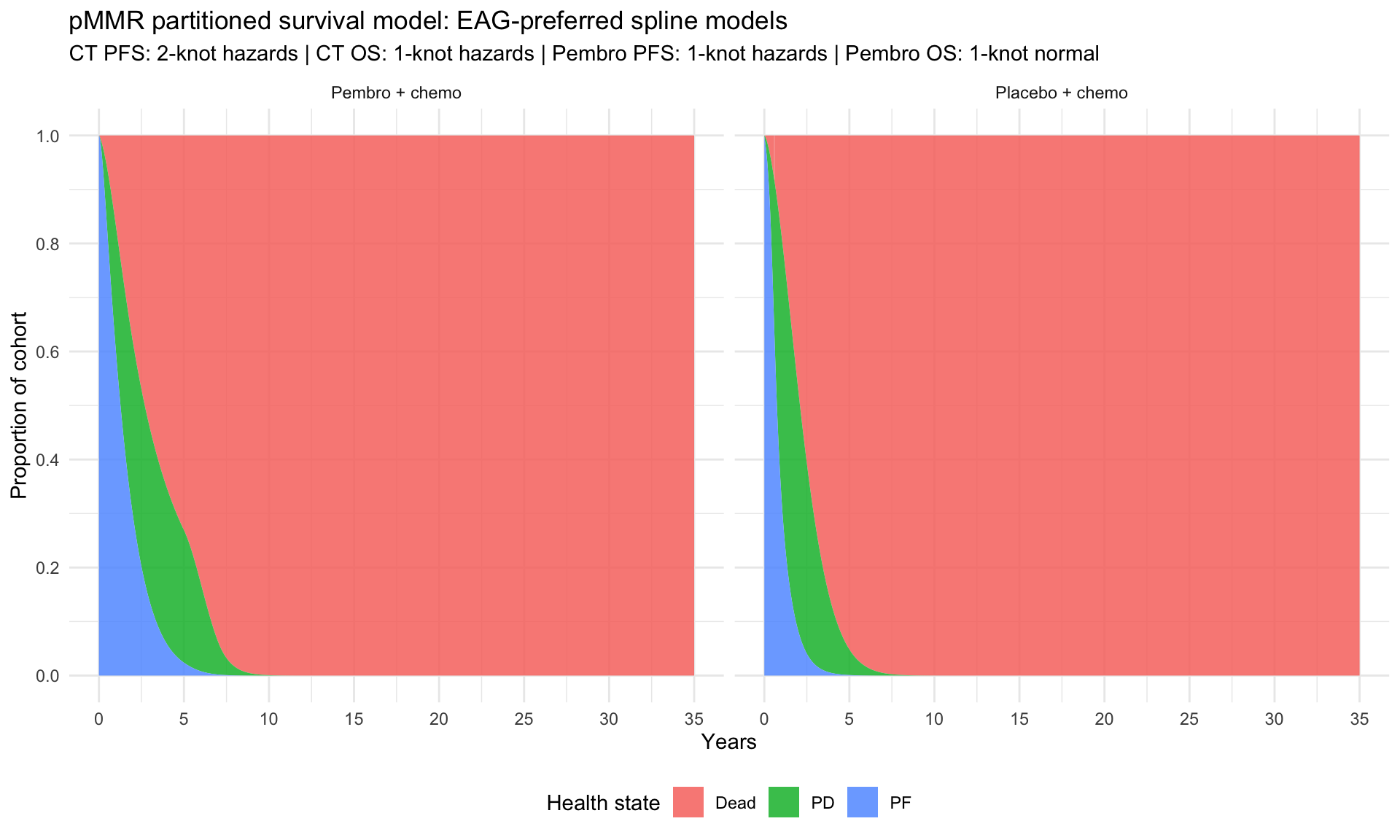
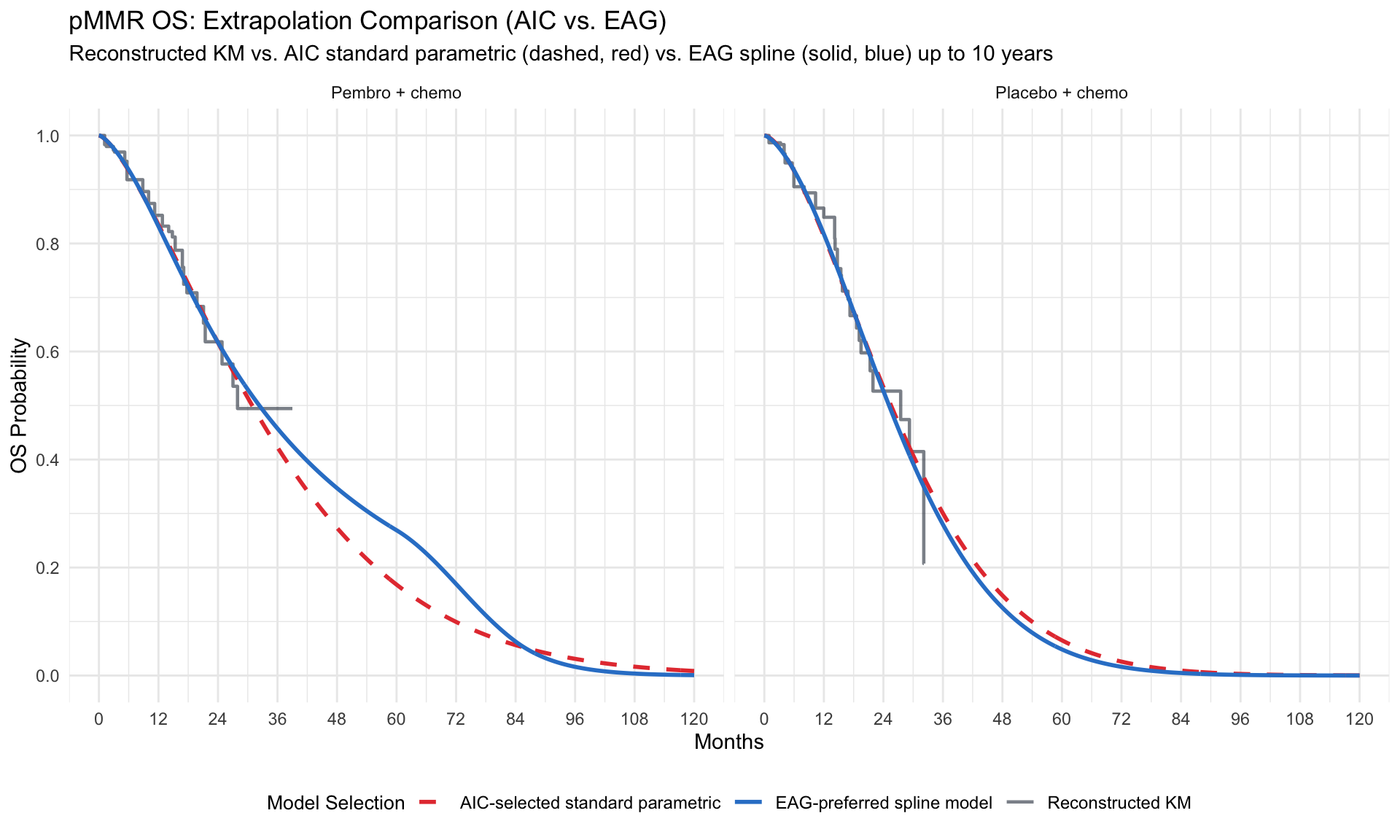
# Define EAG spline specifications for pMMR (Table 2)
eag_pmmr_spline_specs <- tibble::tribble(
~subgroup, ~endpoint, ~treatment, ~k, ~scale, ~dist_label,
"pMMR", "PFS", "placebo_chemo", 2, "hazard", "2-knot hazards",
"pMMR", "OS", "placebo_chemo", 1, "hazard", "1-knot hazards",
"pMMR", "PFS", "pembro_chemo", 1, "hazard", "1-knot hazards",
"pMMR", "OS", "pembro_chemo", 1, "normal", "1-knot normal"
)
# Fit spline models
spline_fit_rows <- vector("list", nrow(eag_pmmr_spline_specs))
for (i in seq_len(nrow(eag_pmmr_spline_specs))) {
spec_i <- eag_pmmr_spline_specs[i, ]
dat_i <- ipd |> filter(
as.character(subgroup) == spec_i$subgroup,
as.character(endpoint) == spec_i$endpoint,
as.character(treatment) == spec_i$treatment
)
res_i <- fit_one_spline(dat_i, spec_i$k, spec_i$scale, spec_i$dist_label)
spline_fit_rows[[i]] <- bind_cols(
tibble(subgroup = spec_i$subgroup,
endpoint = spec_i$endpoint,
treatment = spec_i$treatment),
res_i
)
}
eag_pmmr_spline_fits <- bind_rows(spline_fit_rows)
eag_pmmr_spline_fits |>
select(subgroup, endpoint, treatment, dist_label, n, events, aic, converged, error) |>
kable(digits = 2, caption = "EAG-preferred spline model fitting results for pMMR cohort (based on EAG Report Table 2)", align = "l")